Fast3R是什么
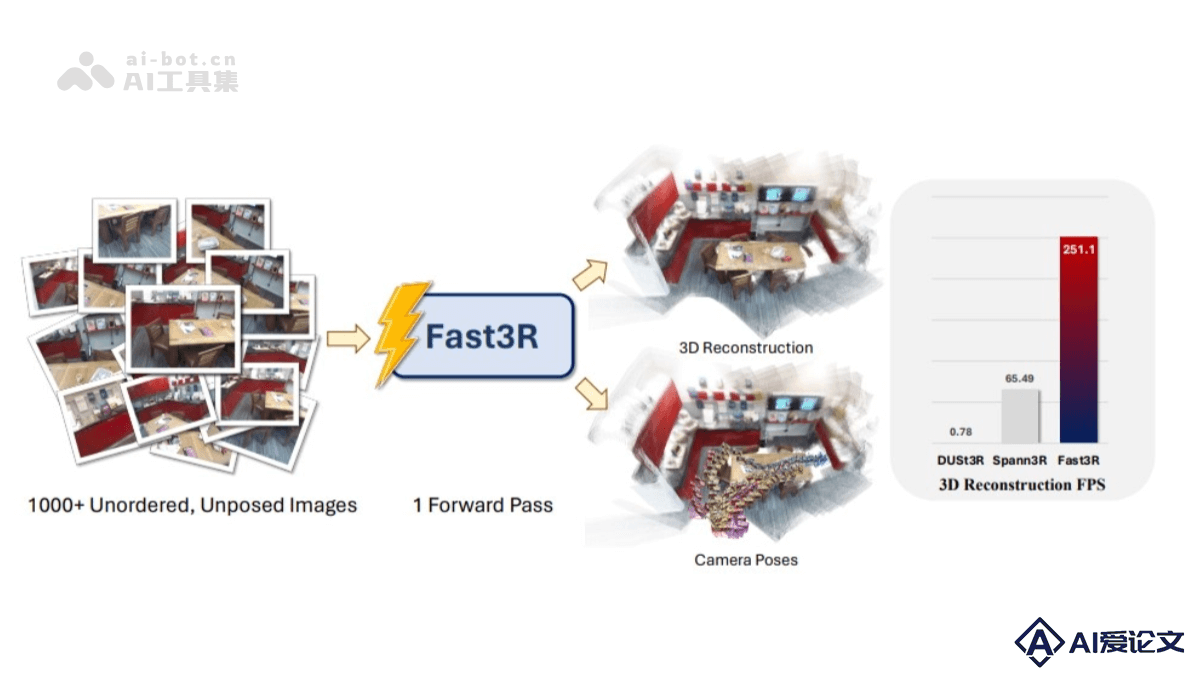
Fast3R是Meta和密歇根大学的研究人员提出的新型的多视图3D重建方法,基于Transformer架构,能在一个前向传播过程中处理1000多张图像,实现高效且可扩展的3D重建。与传统方法相比,Fast3R摒弃了逐对处理图像和全局对齐的复杂步骤,通过并行处理多个视图,提高了推理速度,减少误差累积。核心优势在于并行处理能力和对多视图的支持。能同时处理多个图像,每个图像都可以同时关注其他所有图像,在重建过程中减少误差累积。
来源:爱论文 时间:2025-03-26 09:31:04
Fast3R是Meta和密歇根大学的研究人员提出的新型的多视图3D重建方法,基于Transformer架构,能在一个前向传播过程中处理1000多张图像,实现高效且可扩展的3D重建。与传统方法相比,Fast3R摒弃了逐对处理图像和全局对齐的复杂步骤,通过并行处理多个视图,提高了推理速度,减少误差累积。核心优势在于并行处理能力和对多视图的支持。能同时处理多个图像,每个图像都可以同时关注其他所有图像,在重建过程中减少误差累积。
 相关资讯
更多+
相关资讯
更多+
Fast3R是Meta和密歇根大学的研究人员提出的新型的多视图3D重建方法,基于Transformer架构,能在一个前向传播过程中处理1000多张图像,实现高效且可扩展的3D重建。与传统方法相比,Fast3R摒弃了逐对处理图像和全局对齐的复杂步骤,通过并行处理多个视图,提高了推理速度,减少误差累积。
AI教程资讯
 2023-04-14
2023-04-14

CityDreamer4D是南洋理工大学 S-Lab 团队开发的用于生成无边界 4D 城市的组合生成模型。将动态物体(如车辆)与静态场景(如建筑和道路)分离,通过三个模块——建筑实例生成器、车辆实例生成器和城市背景生成器,基于高效的鸟瞰图场景表示法来生成城市场景。
AI教程资讯
2023-04-14

Tarsier2是字节跳动推出的先进的大规模视觉语言模型(LVLM),生成详细且准确的视频描述,在多种视频理解任务中表现出色。模型通过三个关键升级实现性能提升,将预训练数据从1100万扩展到4000万视频文本对,丰富了数据量和多样性;在监督微调阶段执行精细的时间对齐;基于模型采样自动构建偏好数据,应用直接偏好优化(DPO)训练。
AI教程资讯
2023-04-14

VideoLLaMA3 是阿里巴巴开源的前沿多模态基础模型,专注于图像和视频理解。基于 Qwen 2 5 架构,结合了先进的视觉编码器(如 SigLip)和强大的语言生成能力,能高效处理长视频序列,支持多语言的视频内容分析和视觉问答任务。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载














