3DHM是什么
3DHM(3D Human Motions)是先进的3D人体动作生成技术,加州大学伯克利分校的研究人员推出。能从单张人物照片生成具有3D控制的动态人体视频,实现从静态图像到动态视频的转变。技术通过学习人体不可见部分的先验知识,结合给定的3D运动序列,渲染出具有适当服装和纹理的新身体姿势。3DHM的应用范围广泛,包括电影特效、虚拟现实和游戏开发等,为动画制作和人体动作模拟提供了新的可能性。

来源:爱论文 时间:2025-01-20 14:50:25
3DHM(3D Human Motions)是先进的3D人体动作生成技术,加州大学伯克利分校的研究人员推出。能从单张人物照片生成具有3D控制的动态人体视频,实现从静态图像到动态视频的转变。技术通过学习人体不可见部分的先验知识,结合给定的3D运动序列,渲染出具有适当服装和纹理的新身体姿势。3DHM的应用范围广泛,包括电影特效、虚拟现实和游戏开发等,为动画制作和人体动作模拟提供了新的可能性。
 相关资讯
更多+
相关资讯
更多+
3DHM(3D Human Motions)是先进的3D人体动作生成技术,加州大学伯克利分校的研究人员推出。能从单张人物照片生成具有3D控制的动态人体视频,实现从静态图像到动态视频的转变。技术通过学习人体不可见部分的先验知识,结合给定的3D运动序列,渲染出具有适当服装和纹理的新身体姿势。
AI教程资讯
 2023-04-14
2023-04-14

Diff-Instruct是先进的知识转移方法,用于从预训练的扩散模型中提取知识,指导其他生成模型的训练。它基于一种新的散度度量——积分Kullback-Leibler (IKL) 散度,专为扩散模型设计,通过计算沿扩散过程的KL散度积分来比较分布。
AI教程资讯
2023-04-14
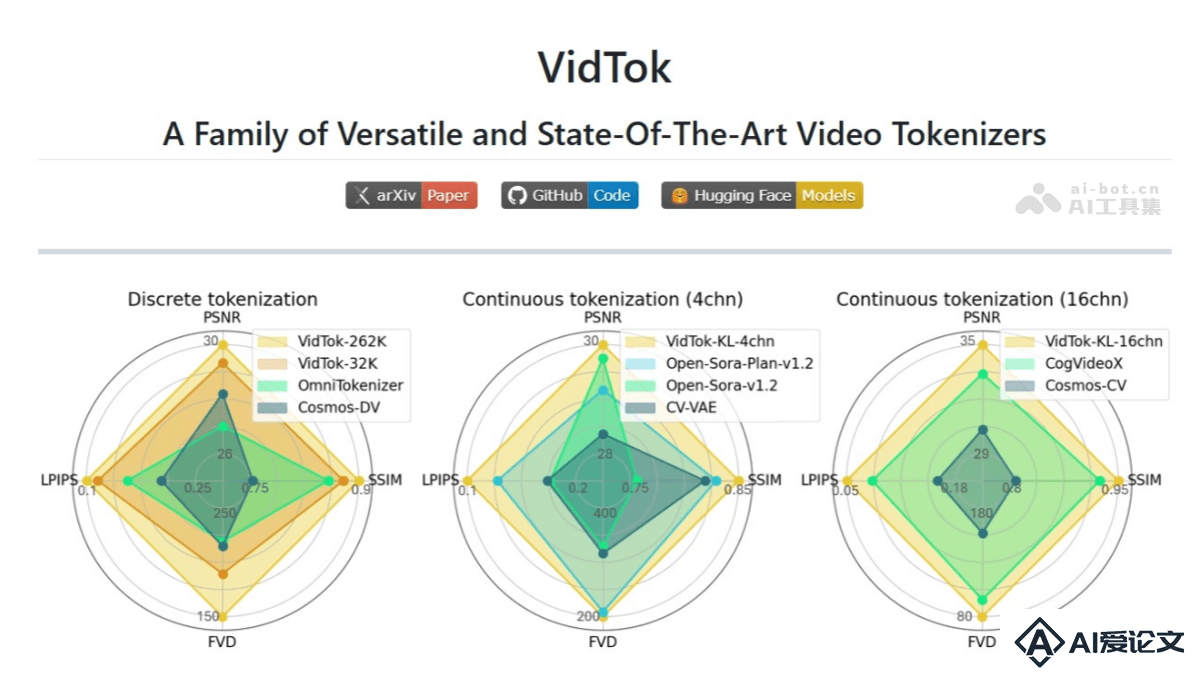
VidTok(Video Tokenizer)是微软开源的先进的视频分词器,通过高效的算法将视频内容转换成一系列“视频词”。支持连续和离散分词化,具有灵活的压缩率和多样化的隐空间,适用于不同的应用场景。
AI教程资讯
2023-04-14

Infinity是字节跳动推出的基于位级自回归建模的视觉生成模型,能根据语言指令生成高分辨率、逼真的图像。Infinity通过无限词汇量的标记器、分类器和位自纠正机制,显著提升图像生成的细节和质量,超越现有的顶级扩散模型,生成一张1024×1024的高质量图像仅需0 8秒,比SD3-Medium快2 6倍,且具有更快的推理速度。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载












