ExVideo是什么
ExVideo是由阿里巴巴和华东师大的研究人员推出的一种视频合成模型的后调优技术,能够扩展现有视频合成模型的时间尺度,以生成更长和帧数更多的视频。该团队基于Stable Video Diffusion模型,训练了一个能够生成长达128帧连贯视频的扩展模型,同时保留了原始模型的生成能力。ExVideo通过优化3D卷积、时间注意力和位置嵌入等时间模块,使模型能够处理更长时间跨度的内容,在保持原始模型生成能力的同时,显著增加了视频帧数,且训练成本较低,特别适合计算资源有限的情况。

ExVideo的功能特点
时间尺度扩展:ExVideo的核心功能之一是扩展视频合成模型的时间尺度,可以处理和生成比原始模型设计时更长的视频序列。通过这种扩展,ExVideo能够生成具有更多帧的视频,从而讲述更完整的故事或展示更长时间的动态场景。后调优策略:ExVideo的后调优策略是其技术的关键部分,通过对Stable Video Diffusion等模型的特定部分进行再训练,ExVideo能够使这些模型生成更长的视频,达到128帧或更多。不仅提高了视频的长度,还保持了模型对各种输入的泛化能力,使得生成的视频多样化且适应性强。参数高效:与传统的训练方法相比,ExVideo采用后调优策略,无需从头开始训练一个全新的模型,而是在现有模型的基础上进行优化,显著减少了所需的参数数量和计算资源,使得模型的扩展更加高效和实用。保持生成能力:在对视频长度进行扩展的同时,ExVideo注重保持视频的质量,生成的视频不仅在时间上有所延长,而且在视觉连贯性、清晰度和整体质量上也能满足高标准。兼容性和通用性:ExVideo的设计考虑到了与多种视频合成模型的兼容性,使其能够广泛应用于不同的视频生成任务。无论是3D卷积、时间注意力还是位置嵌入,ExVideo都能够提供相应的扩展策略,以适应不同的模型架构。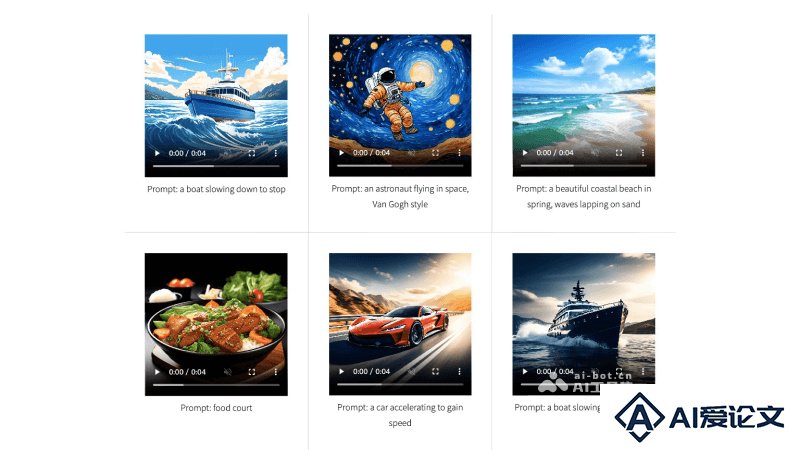
ExVideo的官网入口
官方项目主页:https://ecnu-cilab.github.io/ExVideoProjectPage/GitHub代码库:https://github.com/modelscope/DiffSynth-StudioHugging Face模型下载:https://huggingface.co/ECNU-CILab/ExVideo-SVD-128f-v1ModelScope模型下载:https://www.modelscope.cn/models/ECNU-CILab/ExVideo-SVD-128f-v1/summaryarXiv技术论文:https://arxiv.org/abs/2406.14130ExVideo的技术原理
参数后调优(Post-Tuning):ExVideo采用参数后调优的方法,对现有的视频合成模型进行改进。这包括对模型的特定部分进行再训练,而不是重新训练整个模型,从而提高效率。时间模块扩展:针对视频合成模型中的时间模块,ExVideo提出了扩展策略。这些策略包括对3D卷积层、时间注意力机制和位置嵌入层的优化,以适应更长的视频序列。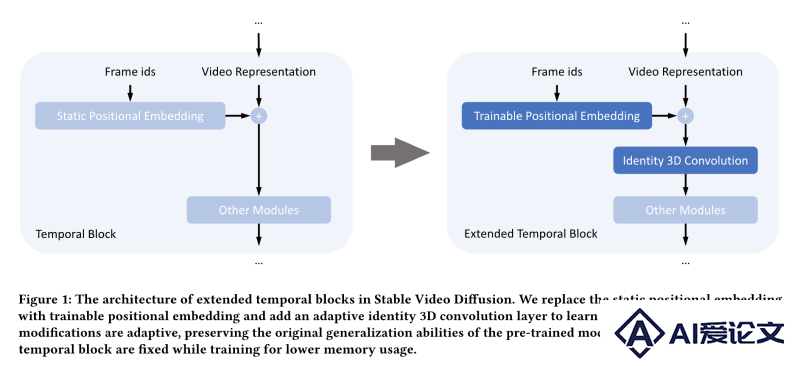 3D卷积层:3D卷积层在视频合成中用于捕捉时间维度上的特征。ExVideo保留了原始模型中的3D卷积层,因为它们能够适应不同的时间尺度,而无需额外的微调。时间注意力机制:为了提高模型处理长时间序列的能力,ExVideo对时间注意力模块进行了微调。这有助于模型更好地理解视频内容的时间连贯性。位置嵌入:传统的视频合成模型可能使用静态或可训练的位置嵌入来表示视频中的帧顺序。ExVideo通过引入可训练的位置嵌入,并通过循环模式初始化,来适应更长的视频序列。身份3D卷积层(Identity 3D Convolution):在位置嵌入层之后,ExVideo引入了一个额外的身份3D卷积层,用于学习长期视频特征。这个层在训练前初始化为单位矩阵,确保不会改变视频表示,保持与原始模型的一致性。工程优化:为了在有限的计算资源下进行有效的训练,ExVideo采用了多种工程优化技术,如参数冻结、混合精度训练、梯度检查点技术和Flash Attention,以及使用DeepSpeed库来分片优化器状态和梯度。训练过程:ExVideo使用了一个公开可用的数据集OpenSoraPlan2进行训练,该数据集包含大量视频,以此来增强模型生成多样化视频的能力。损失函数和噪声调度:在训练过程中,ExVideo保持了与原始模型一致的损失函数和噪声调度策略,确保了模型训练的稳定性和效率。
3D卷积层:3D卷积层在视频合成中用于捕捉时间维度上的特征。ExVideo保留了原始模型中的3D卷积层,因为它们能够适应不同的时间尺度,而无需额外的微调。时间注意力机制:为了提高模型处理长时间序列的能力,ExVideo对时间注意力模块进行了微调。这有助于模型更好地理解视频内容的时间连贯性。位置嵌入:传统的视频合成模型可能使用静态或可训练的位置嵌入来表示视频中的帧顺序。ExVideo通过引入可训练的位置嵌入,并通过循环模式初始化,来适应更长的视频序列。身份3D卷积层(Identity 3D Convolution):在位置嵌入层之后,ExVideo引入了一个额外的身份3D卷积层,用于学习长期视频特征。这个层在训练前初始化为单位矩阵,确保不会改变视频表示,保持与原始模型的一致性。工程优化:为了在有限的计算资源下进行有效的训练,ExVideo采用了多种工程优化技术,如参数冻结、混合精度训练、梯度检查点技术和Flash Attention,以及使用DeepSpeed库来分片优化器状态和梯度。训练过程:ExVideo使用了一个公开可用的数据集OpenSoraPlan2进行训练,该数据集包含大量视频,以此来增强模型生成多样化视频的能力。损失函数和噪声调度:在训练过程中,ExVideo保持了与原始模型一致的损失函数和噪声调度策略,确保了模型训练的稳定性和效率。  相关资讯
相关资讯 2023-04-14
2023-04-14



 下载
下载














