Parler-TTS是什么
Parler-TTS是由Hugging Face推出的一款开源的文本到语音(TTS)模型,能够通过输入提示描述模仿特定说话者的风格(性别、音调、说话风格等),生成高质量、听起来自然的语音。该轻量级的TTS模型是完全开源的,包括所有数据集、预处理、训练代码和权重都公开,旨在促进高质量、可控制的TTS模型的创新发展。Parler-TTS的架构基于MusicGen,包含文本编码器、解码器和音频编解码器,通过集成文本描述和添加嵌入层优化了声音生成。

Parler-TTS的官网入口
GitHub源码库:https://github.com/huggingface/parler-ttsHugging Face模型地址:https://github.com/huggingface/parler-ttsHugging Face在线Demo体验地址:https://huggingface.co/spaces/parler-tts/parler_tts_miniParler-TTS的功能特性
高质量语音生成:Parler-TTS能够根据文本输入生成高质量、自然听起来的语音,模仿不同的说话风格,如性别、音高和表达方式等。风格多样的语音输出:通过详细的文本描述,用户可以控制生成的语音风格,包括说话者的年龄、情感、速度和环境等特征。开源架构:Parler-TTS基于MusicGen架构,包含文本编码器、解码器和音频编解码器,允许研究者和开发者自由访问和修改代码,以适应不同的需求和应用。易于安装和使用:Parler-TTS提供了简单的安装指令,用户可以通过一行命令安装,并提供了易于理解的代码示例,使得即使是初学者也能快速上手使用。自定义训练和微调:用户可以根据自己的数据集对Parler-TTS进行训练和微调,以生成特定风格或口音的语音。伦理和隐私保护:Parler-TTS避免了使用可能侵犯隐私的声音克隆技术,而是通过文本提示来控制语音生成,确保了技术的伦理性和合规性。如何体验Parler-TTS
访问Parler-TTS的Hugging Face Demo,然后在Input Text处输入你想要转录的文字在Description处输入对声音的提示描述最后点击Generate Audio即可生成声音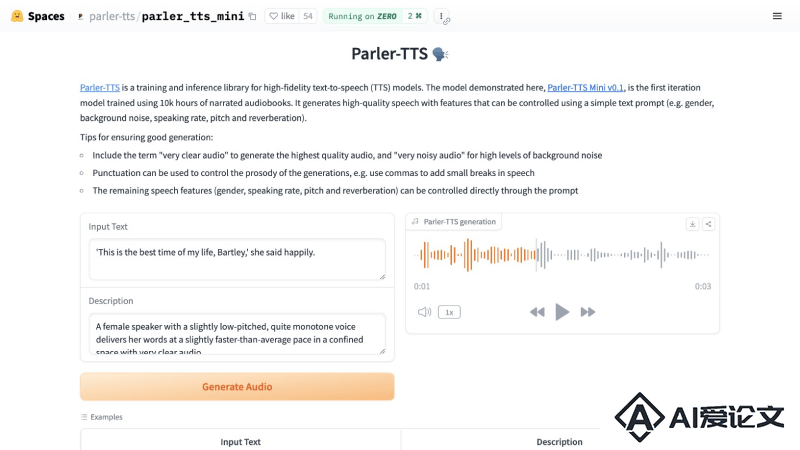
Parler-TTS的技术架构
Parler-TTS的架构是一个高度灵活和可定制的系统,基于MusicGen架构进行了一些关键的改进和调整:
文本编码器:文本编码器的作用是将文本描述映射到一系列隐藏状态表示。Parler-TTS使用的是一个冻结的文本编码器,该编码器完全初始化自Flan-T5模型。这意味着编码器的参数在训练过程中不会改变,它仅仅用于将输入的文本转换为模型可以理解的内部表示。Parler-TTS解码器:解码器是一个语言模型,它基于编码器的隐藏状态表示自回归地生成音频标记(或称为代码)。这个过程中,解码器会逐步生成语音的音频表示,每一步都会考虑到之前的输出和文本描述,从而生成连贯且符合描述的语音。音频编解码器:音频编解码器的作用是将解码器预测的音频标记转换回可听的音频波形。Parler-TTS使用的是Descript提供的DAC模型,但也可以选择使用其他编解码器模型,例如EnCodec。架构的改进:Parler-TTS在MusicGen架构的基础上做了一些细微的调整,以提高模型的性能和灵活性。文本描述不仅通过文本编码器处理,还用于解码器的交叉注意力层,这使得解码器能够更好地结合文本描述和音频生成。文本提示通过嵌入层处理后与解码器输入的隐藏状态进行拼接,这样可以将文本提示的语义信息直接融入到语音生成的过程中。音频编码器选择DAC而不是Encodec,因为DAC在质量上表现更佳。 相关资讯
相关资讯 2023-04-14
2023-04-14



 下载
下载














