StreamingT2V是什么
StreamingT2V是由PicsArt AI研究团队推出的一个文本到视频的生成模型,旨在解决现有模型仅能生成16帧或24帧的高质量短视频,而当在生成长视频时则会遇到如视频质量下降、场景转换不一致和视频停滞等问题的挑战。StreamingT2V通过引入条件注意模块(CAM)和外观保持模块(APM)以及随机混合方法,实现了长视频(最长达1200帧、时长2分钟)的流畅生成,确保了时间上的连贯性和与文本描述的紧密对齐。该方法不仅提高了视频的质量,还使得视频内容更加丰富和动态,从而在长视频生成领域取得了显著进步。

StreamingT2V的官网入口
官方项目主页:https://streamingt2v.github.io/GitHub代码库:https://github.com/Picsart-AI-Research/StreamingT2V(模型和源码待上线)arXiv研究论文:https://arxiv.org/abs/2403.14773StreamingT2V的功能特性
长视频生成:StreamingT2V能够根据文本描述生成长视频(80, 240, 600, 1200帧或更多),远超传统模型通常生成的短视频长度。时间连贯性:生成的视频帧之间具有平滑的过渡和一致性,避免了生成长视频时常见的硬切换或不连贯现象。高质量图像帧:该模型注重帧级别的图像质量,保证即使在视频较长的情况下,每一帧的图像也能保持清晰和细腻。文本对齐:StreamingT2V生成的视频紧密对齐于输入的文本提示描述,确保视频内容与用户的文本指导保持一致。视频增强:利用随机混合方法,StreamingT2V可以在不引入块间不一致性的情况下,对生成的视频进行质量增强,提高视频的分辨率和视觉效果。StreamingT2V的工作流程
StreamingT2V的工作流程可以分为以下几个主要阶段:
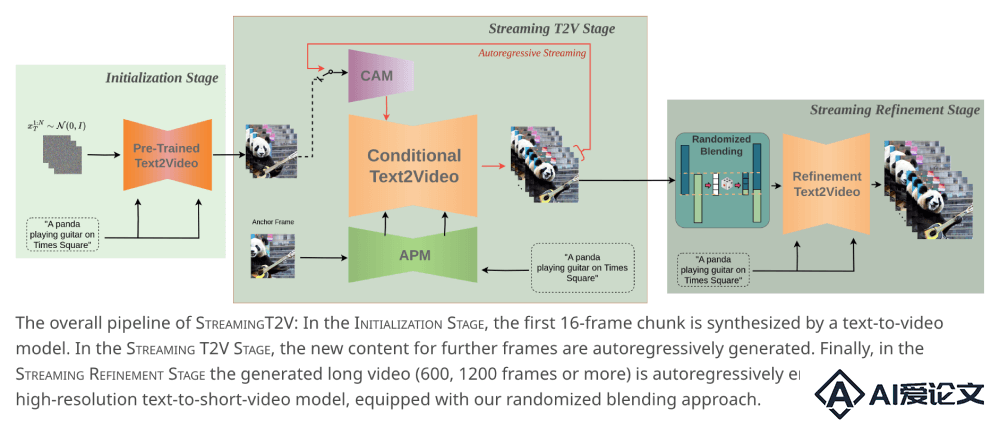 初始化阶段(Initialization Stage):在这一阶段,首先使用预训练的文本到视频模型(例如Modelscope)来合成一个初始的视频块,通常是一个短的16帧的视频序列。流式生成阶段(Streaming T2V Stage):接下来,模型进入自回归的长视频生成过程。在这个阶段,StreamingT2V使用条件注意模块(CAM)和外观保持模块(APM)来生成长视频的后续帧。CAM利用短期记忆,通过注意力机制关注前一个视频块的特征,从而实现块之间的平滑过渡。APM则利用长期记忆,从初始视频块中提取关键的视觉特征,确保在整个视频生成过程中保持场景和对象的一致性。流式细化阶段(Streaming Refinement Stage):在生成了足够长的视频(例如80, 240, 600, 1200帧或更多)后,模型进入细化阶段。在这一阶段,使用高分辨率的文本到视频模型(例如MS-Vid2Vid-XL)对生成的视频进行自回归增强。通过随机混合方法,对连续的24帧视频块进行增强,同时保持块之间的平滑过渡,从而提高视频的整体质量和分辨率。
初始化阶段(Initialization Stage):在这一阶段,首先使用预训练的文本到视频模型(例如Modelscope)来合成一个初始的视频块,通常是一个短的16帧的视频序列。流式生成阶段(Streaming T2V Stage):接下来,模型进入自回归的长视频生成过程。在这个阶段,StreamingT2V使用条件注意模块(CAM)和外观保持模块(APM)来生成长视频的后续帧。CAM利用短期记忆,通过注意力机制关注前一个视频块的特征,从而实现块之间的平滑过渡。APM则利用长期记忆,从初始视频块中提取关键的视觉特征,确保在整个视频生成过程中保持场景和对象的一致性。流式细化阶段(Streaming Refinement Stage):在生成了足够长的视频(例如80, 240, 600, 1200帧或更多)后,模型进入细化阶段。在这一阶段,使用高分辨率的文本到视频模型(例如MS-Vid2Vid-XL)对生成的视频进行自回归增强。通过随机混合方法,对连续的24帧视频块进行增强,同时保持块之间的平滑过渡,从而提高视频的整体质量和分辨率。  相关资讯
相关资讯 2023-04-14
2023-04-14



 下载
下载














