StreamMultiDiffusion – 实时生成和编辑图像的交互式框架
来源:爱论文
时间:2025-05-08 12:50:50
StreamMultiDiffusion是什么
StreamMultiDiffusion是一个开源的实时交互式的图像生成框架,结合了扩散模型的高质量图像合成能力和区域控制的灵活性,可根据用户指定的区域文本提示生成实时、交互式、多文本到图像。该框架的目的是提高图像生成的速度和用户交互性,使得用户能够实时地生成和编辑图像。
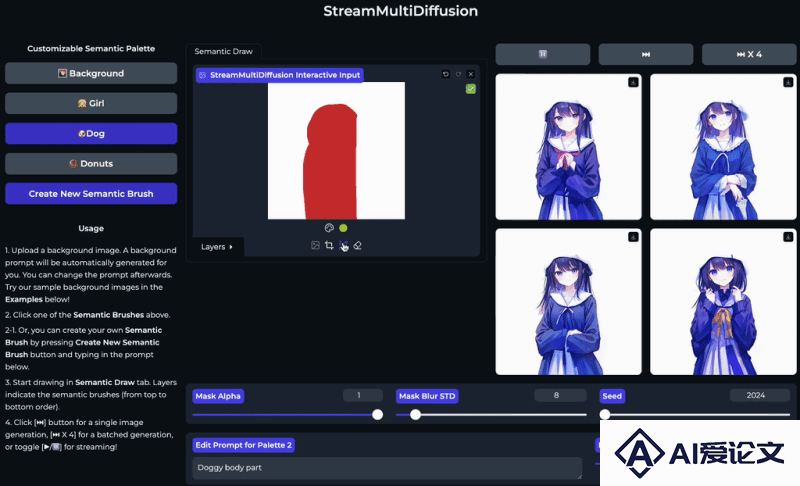
StreamMultiDiffusion的官网入口
GitHub源码:https://github.com/ironjr/StreamMultiDiffusionHugging Face Demo:https://huggingface.co/spaces/ironjr/SemanticPalettearXiv研究论文:https://arxiv.org/abs/2403.09055
StreamMultiDiffusion的功能特性
实时图像生成:StreamMultiDiffusion能够实现快速的图像生成,使得用户可以实时地看到由文本描述转换成的图像。这种实时性大大提高了用户体验,并允许即时的迭代和修改。指定区域文本到图像生成:用户可以通过指定的文本提示和手绘区域来生成图像的特定部分。这意味着用户可以控制图像的特定区域,如指定某个区域应包含“鹰”或“女孩”,而其他区域则由模型根据上下文自动生成。Semantic Palette(语义画板)允许用户通过直观的方式与模型交互,类似于使用画笔在画布上绘制。用户可以通过输入文本提示和绘制区域来“绘制”图像,从而实现高度个性化的图像创作。高质量图像输出:利用强大的扩散模型,StreamMultiDiffusion能够生成高分辨率和高质量的图像,满足专业级图像生成的需求。直观的用户交互界面:StreamMultiDiffusion提供了一个直观的用户界面,使得用户可以通过简单的操作来控制图像生成过程,包括上传背景图像、输入文本提示、绘制区域以及实时查看生成结果。
StreamMultiDiffusion的工作原理
多提示流批处理架构:StreamMultiDiffusion将模型重构为一个新的流批处理架构,可同时处理多个文本提示和对应的区域掩码(masks)。该架构通过在每个时间步输入新的图像和上一批处理过的图像,使得模型能够在不同的时间步处理不同阶段的图像生成任务,从而提高整体的生成速度和效率。快速推理技术:为了实现实时生成,StreamMultiDiffusion采用了快速推理技术,如Latent Consistency Models(LCM)和其LoRA(Low-rank Adaptation)扩展,减少了从扩散模型生成图像所需的推理步骤,从而加快了生成速度。区域控制:StreamMultiDiffusion允许用户通过手绘区域和文本提示来控制图像的特定部分。这些区域掩码指导模型在指定区域内生成与文本提示相对应的内容,从而实现对图像细节的精细控制。稳定化技术:为了确保在快速推理的同时保持图像质量,StreamMultiDiffusion引入了几种稳定化技术:Latent Pre-Averaging:在进行区域合成之前,先对潜在表示进行预平均,以减少不同区域间的突兀感。Mask-Centering Bootstrapping:在生成过程的早期阶段,将区域的中心引导到图像的中心位置,以确保模型不会在后续步骤中忽略这些区域。Quantized Masks:通过量化掩码来平滑区域边界,使得不同区域之间的过渡更加自然。Semantic Palette(语义画板):这是StreamMultiDiffusion提出的一个新的交互式图像生成范式,允许用户通过文本提示和手绘区域来“绘制”图像。用户可以实时地调整这些输入,模型将根据这些输入生成相应的图像。实时反馈和迭代:StreamMultiDiffusion提供了一个实时反馈机制,用户可以通过观察生成的图像流来评估模型的输出,并根据需要实时调整文本提示和区域掩码。这种实时反馈机制使得用户可以快速迭代和优化生成的图像。
如何使用StreamMultiDiffusion
访问StreamMultiDiffusion的Hugging Face空间点击Background输入画面背景提示,若绘制整个画板,则不需要输入背景提示选择语义画板中的画笔并编辑画笔的提示词,然后开始绘制绘制完成后点击右侧的Generate按钮等待图像生成


 相关资讯
相关资讯 2023-04-14
2023-04-14



 下载
下载














