DUSt3R是什么
DUSt3R(Dense and Unconstrained Stereo 3D Reconstruction,密集无约束立体三维重建)是由来自芬兰阿尔托大学和Naver欧洲实验室的研究人员推出的一个3D重建框架,旨在简化从任意图像集合中重建三维场景的过程,而无需事先了解相机校准或视点位置的信息。该方法将成对重建问题视为点图的回归问题,放宽了传统投影相机模型的约束,还引入了全局对齐策略以处理多个图像对。

DUSt3R的官网入口
官方项目主页:https://dust3r.europe.naverlabs.com/GitHub代码库:https://github.com/naver/dust3rarXiv研究论文:https://arxiv.org/abs/2312.14132DUSt3R的主要功能
快速3D重建:DUSt3R能够在极短的时间内(不到2秒钟)从输入图片中重建出3D模型,对于实时应用或快速原型制作非常有用。无需相机校准:与传统的3D重建技术不同,DUSt3R不需要任何相机校准或视点姿势的先验信息。这意味着用户无需进行复杂的设置,只需提供图片即可。多视图立体重建(MVS):DUSt3R能够处理多视图立体重建任务,即使在提供超过两张输入图像的情况下,也能有效地将所有成对的点图表示为一个共同的参考框架。单目和双目重建:DUSt3R统一了单目和双目重建的情况,即可以使用单个图像或成对的图像来进行3D重建。生成多种类型的3D视觉图:除了3D重建,DUSt3R还能生成深度图,可以理解场景中物体的相对位置和距离。此外,DUSt3R还能输出置信度图,用于评估重建结果的准确性,以及用于3D建模和可视化的点云图。DUSt3R的技术原理
点图(Pointmaps):DUSt3R使用点图作为其核心表示,这是一种密集的2D场,其中包含了3D点的信息。点图为每个像素提供了一个与之对应的3D点,从而在图像像素和3D场景点之间建立了直接的对应关系。Transformer网络架构:DUSt3R基于标准的Transformer编码器和解码器构建其网络架构。该架构允许模型利用强大的预训练模型,从而在没有显式几何约束的情况下,从输入图像中学习到丰富的几何和外观信息。端到端训练:DUSt3R通过端到端的方式进行训练,可以直接从图像对中学习到点图,而不需要进行复杂的多步骤处理,如特征匹配、三角测量等。全局对齐策略:当处理多于两张图像时,DUSt3R提出了一种全局对齐策略,该策略能够将所有成对点图表达在共同的参考框架中,能够处理多个图像对,这对于多视图3D重建尤为重要。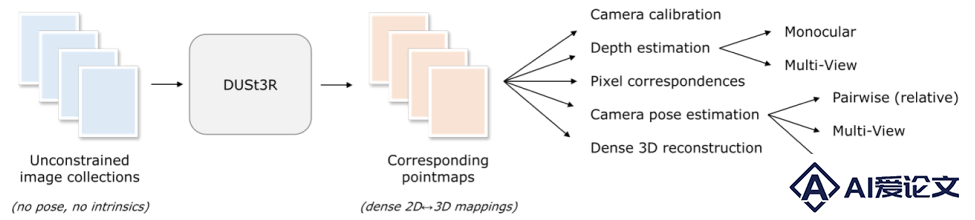 多任务学习:DUSt3R能够在训练过程中同时学习多个相关任务,如深度估计、相机参数估计、像素对应关系等。这种多任务学习策略使得模型能够更全面地理解场景的几何结构。
多任务学习:DUSt3R能够在训练过程中同时学习多个相关任务,如深度估计、相机参数估计、像素对应关系等。这种多任务学习策略使得模型能够更全面地理解场景的几何结构。  相关资讯
相关资讯 2023-04-14
2023-04-14



 下载
下载














