ConsiStory是什么
ConsiStory是由NVIDIA和特拉维夫大学的研究人员共同开发的一种无需训练的文本生成图像的方法,可以实现让图像在保持风格和主题不变的情况下,遵循不同的文本提示快速且自然地扩展到不同的场景下。ConsiStory的核心思想是在图像生成过程中,通过共享预训练文生图模型的内部激活来实现主题的一致性。这种方法不需要对模型进行任何形式的优化或预训练,从而大大简化了生成一致性图像的过程。

ConsiStory的官网入口
官方项目主页:https://consistory-paper.github.io/Arxiv研究论文:https://arxiv.org/abs/2402.03286GitHub源代码库:即将推出ConsiStory的主要特点
无需训练:ConsiStory不需要对预训练的文本到图像(T2I)模型进行任何形式的优化或个性化训练,即用户可以直接使用现有的模型来生成一致性的图像,大大节省了时间和资源。一致性主题生成:该方法能够生成一系列图像,这些图像在不同文本提示下保持相同的主题身份,例如相同的人物、动物或物体。这对于需要一致视觉元素的应用(如故事书、角色设计、虚拟资产创建等)非常有用。跨帧一致性:ConsiStory通过内部激活共享和注意力机制,确保生成的图像在主题特征上保持一致,即使在不同的背景和情境下。布局多样性:为了增加生成图像的多样性,ConsiStory采用了注意力丢弃和查询特征混合等技术,以避免图像布局的过度一致性。兼容性:该方法与现有的图像编辑工具(如ControlNet)兼容,可以结合使用以实现更复杂的图像控制。快速生成:由于不需要训练步骤,ConsiStory能够快速生成图像,比现有的最先进技术(SoTA)快约20倍。ConsiStory的技术原理
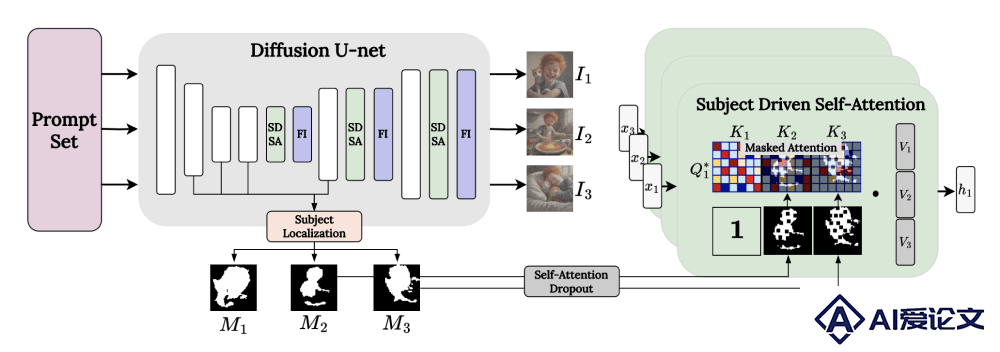 主题定位:在生成过程的每一步,ConsiStory首先在每张生成的图像中定位主题。这是通过分析模型的交叉注意力特征来完成的,这些特征有助于识别图像中可能包含主题的区域。主题驱动的共享注意力:ConsiStory扩展了自注意力机制,允许一个图像中的查询不仅关注自身图像的特征,还能关注其他图像中与主题相关的特征。这样,相同主题的不同实例可以在生成过程中相互影响,从而保持一致性。为了限制背景和布局的一致性,ConsiStory使用主题掩码来确保只有主题相关的特征被共享。布局多样性增强:为了保持生成图像的多样性,ConsiStory采用了两种策略:一是将非一致性采样步骤中的特征与生成的特征混合;二是在共享注意力过程中引入随机的注意力丢弃,以减少不同图像之间的过度一致性。特征注入:为了进一步提高主题一致性,特别是在细节上,ConsiStory引入了特征注入机制。通过构建跨图像的密集对应关系图(使用DIFT特征),ConsiStory能够在不同图像之间精确地对齐和混合特征,以增强主题的一致性。锚定图像和可重用主题:为了提高计算效率,ConsiStory可以选择一部分生成图像作为“锚定图像”。在共享注意力步骤中,只有锚定图像会共享和接收其他图像的特征。这不仅减少了计算负担,还提高了生成质量,并允许在新场景中重用相同的主题。多主题一致性生成:ConsiStory能够处理包含多个主题的图像。通过简单地取所有主题掩码的并集,就可以在单个图像中保持多个主题的一致性。
主题定位:在生成过程的每一步,ConsiStory首先在每张生成的图像中定位主题。这是通过分析模型的交叉注意力特征来完成的,这些特征有助于识别图像中可能包含主题的区域。主题驱动的共享注意力:ConsiStory扩展了自注意力机制,允许一个图像中的查询不仅关注自身图像的特征,还能关注其他图像中与主题相关的特征。这样,相同主题的不同实例可以在生成过程中相互影响,从而保持一致性。为了限制背景和布局的一致性,ConsiStory使用主题掩码来确保只有主题相关的特征被共享。布局多样性增强:为了保持生成图像的多样性,ConsiStory采用了两种策略:一是将非一致性采样步骤中的特征与生成的特征混合;二是在共享注意力过程中引入随机的注意力丢弃,以减少不同图像之间的过度一致性。特征注入:为了进一步提高主题一致性,特别是在细节上,ConsiStory引入了特征注入机制。通过构建跨图像的密集对应关系图(使用DIFT特征),ConsiStory能够在不同图像之间精确地对齐和混合特征,以增强主题的一致性。锚定图像和可重用主题:为了提高计算效率,ConsiStory可以选择一部分生成图像作为“锚定图像”。在共享注意力步骤中,只有锚定图像会共享和接收其他图像的特征。这不仅减少了计算负担,还提高了生成质量,并允许在新场景中重用相同的主题。多主题一致性生成:ConsiStory能够处理包含多个主题的图像。通过简单地取所有主题掩码的并集,就可以在单个图像中保持多个主题的一致性。  相关资讯
相关资讯 2023-04-14
2023-04-14



 下载
下载














