DemoFusion是什么
DemoFusion是一个旨在低成本进行高分辨率图像生成的技术框架,通过扩展现有的开源生成人工智能模型(如Stable Diffusion),使得这些模型能够在不进行额外训练和不产生过高内存需求的情况下,将模糊的低分辨率图像变得更加高清(放大4倍、16倍甚至更高分辨率)。DemoFusion采用渐进式增强、跳跃残差和扩张采样机制来实现更高分辨率的图像生成,对于资源有限的用户来说,达成类似于Magnific AI的解决方案。

DemoFusion的官网入口
官方项目主页:https://ruoyidu.github.io/demofusion/demofusion.htmlArxiv研究论文:https://arxiv.org/abs/2311.16973GitHub代码库:https://github.com/PRIS-CV/DemoFusionHugging Face运行地址:Image to Image版本:https://huggingface.co/spaces/radames/Enhance-This-DemoFusion-SDXLText to Image版本:https://huggingface.co/spaces/fffiloni/DemoFusionReplicate运行地址:Image to Image版本:https://replicate.com/lucataco/demofusion-enhanceText to Image版本:https://replicate.com/lucataco/demofusionGoogle Colab运行地址:https://colab.research.google.com/github/camenduru/DemoFusion-colab/blob/main/DemoFusion_colab.ipynb
DemoFusion的功能特色
高分辨率图像生成:DemoFusion能够将预训练的GenAI模型(如SDXL)的图像生成能力扩展到更高的分辨率,例如从1024×1024像素提升到4096×4096像素或更高,而无需对模型进行额外的训练。渐进式上采样:通过逐步增加图像分辨率的方式,DemoFusion允许用户在生成过程中逐步细化图像细节,同时保持图像的整体质量和语义一致性。全局语义一致性:通过跳跃残差和扩张采样机制,DemoFusion能够在生成高分辨率图像时保持全局的语义一致性,避免局部区域的重复和结构扭曲。快速迭代:由于渐进式上采样的特性,DemoFusion允许用户在生成过程中快速预览低分辨率的结果,从而在等待高分辨率图像生成完成之前,对图像的布局和风格进行快速迭代和调整。无需额外硬件:DemoFusion能够在消费级的硬件(如RTX 3090 GPU)上运行,这意味着用户不需要昂贵的硬件投资就能生成高分辨率的图像。易于集成:DemoFusion作为一个插件式的框架,可以轻松地与现有的AI生成模型集成,使得研究人员和开发者能够快速地将高分辨率图像生成能力应用到他们的项目中。丰富的应用场景:DemoFusion不仅适用于艺术创作,还可以用于各种需要高分辨率图像的领域,如游戏开发、电影制作、虚拟现实等。DemoFusion的工作原理
DemoFusion的工作原理基于几个关键步骤和机制,这些步骤共同作用以生成高分辨率的图像。以下是其主要的工作流程:
初始化(Initialization):DemoFusion首先从一个低分辨率的图像开始,这个图像是通过一个预训练的潜在扩散模型(如SDXL)生成的。渐进式上采样(Progressive Upscaling):从低分辨率图像开始,DemoFusion通过迭代过程逐步增加图像的分辨率。这个过程涉及到将当前分辨率的图像上采样到更高的分辨率,然后通过扩散过程引入噪声,最后通过去噪过程恢复图像。这个过程重复进行,每次都在更高的分辨率上进行,以逐渐增加图像的细节。跳跃残差(Skip Residual):在去噪过程中,DemoFusion利用之前迭代步骤中的噪声反转表示作为跳跃残差。这有助于在生成过程中保持图像的全局结构,同时允许局部细节的优化。扩张采样(Dilated Sampling):为了增强每个去噪路径的全局上下文,DemoFusion引入了扩张采样。这意味着在潜在空间中,通过扩张采样来获取全局表示,然后这些全局表示被用于指导局部去噪路径,以生成具有全局一致性的图像内容。局部和全局路径融合(Fusing Local and Global Paths):在每个迭代步骤中,DemoFusion将局部去噪路径(通过扩张采样得到的局部潜在表示)和全局去噪路径(通过跳跃残差得到的全局潜在表示)结合起来,以生成最终的高分辨率图像。解码(Decoding):最后,通过一个解码器将最终的潜在表示转换回图像空间,得到高分辨率的输出图像。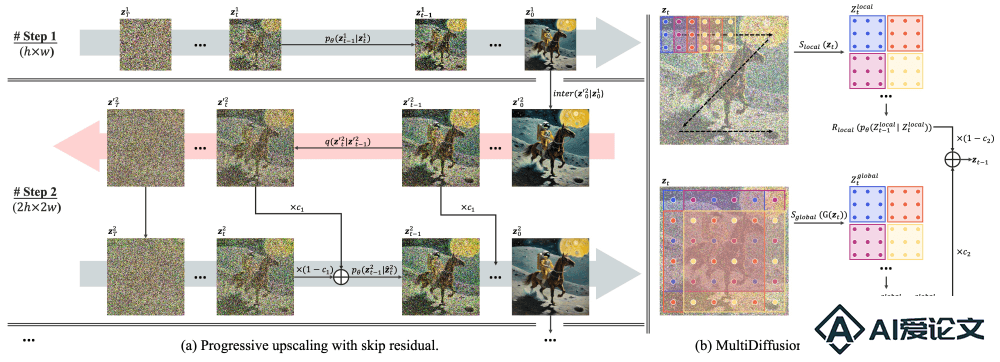
DemoFusion的这些步骤和机制共同作用,使得它能够在不进行额外训练的情况下,有效地生成具有丰富细节和良好全局一致性的高分辨率图像。
如何使用DemoFusion
访问DemoFusion的Replicate或Hugging Face运行地址上传你要放大的图片或使用示例图片输入prompt提示词描述图片画面调节Seed值并设置Demofusion参数最后点击Run运行,等待图片高清放大
 相关资讯
相关资讯 2023-04-14
2023-04-14



 下载
下载














