Kimi-Audio是什么
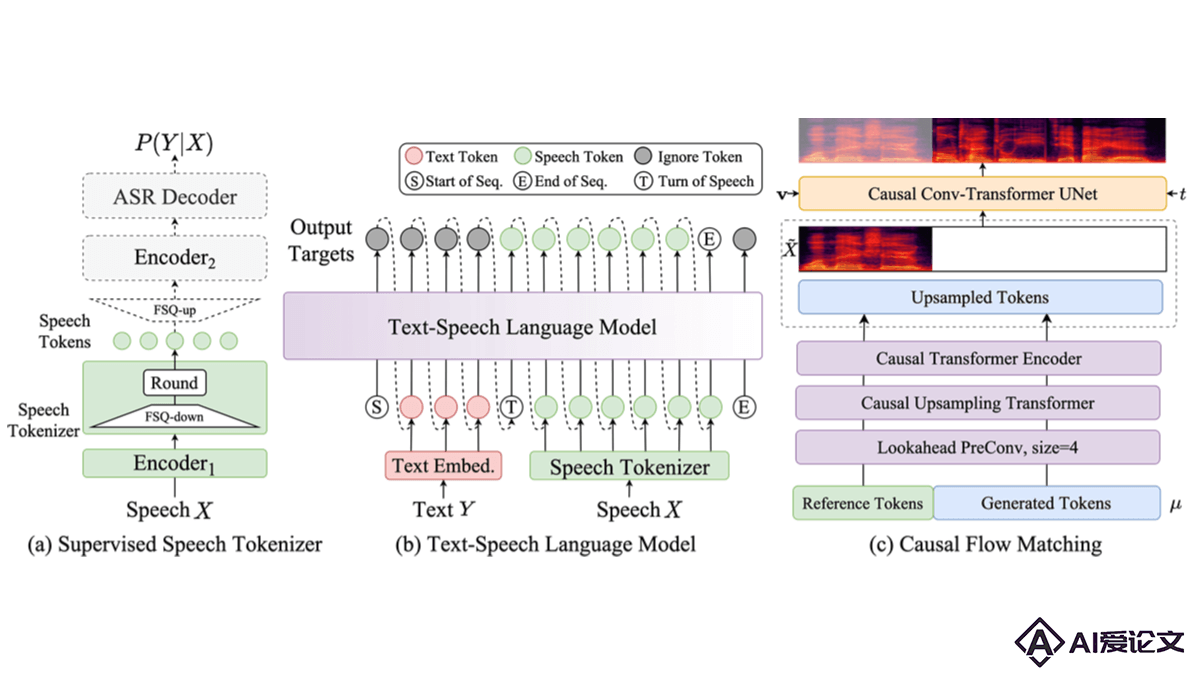
Kimi-Audio 是 Moonshot AI 推出的开源音频基础模型,专注于音频理解、生成和对话任务。在超过 1300 万小时的多样化音频数据上进行预训练,具备强大的音频推理和语言理解能力。核心架构采用混合音频输入(连续声学 + 离散语义标记),结合基于 LLM 的设计,支持并行生成文本和音频标记,同时通过分块流式解码器实现低延迟音频生成。

来源:爱论文 时间:2025-05-15 13:52:30
Kimi-Audio 是 Moonshot AI 推出的开源音频基础模型,专注于音频理解、生成和对话任务。在超过 1300 万小时的多样化音频数据上进行预训练,具备强大的音频推理和语言理解能力。核心架构采用混合音频输入(连续声学 + 离散语义标记),结合基于 LLM 的设计,支持并行生成文本和音频标记,同时通过分块流式解码器实现低延迟音频生成。
 相关资讯
更多+
相关资讯
更多+
Kimi-Audio 是 Moonshot AI 推出的开源音频基础模型,专注于音频理解、生成和对话任务。在超过 1300 万小时的多样化音频数据上进行预训练,具备强大的音频推理和语言理解能力。
AI教程资讯
 2023-04-14
2023-04-14

Firefly Image Model 4 是 Adobe 最新推出的图像生成模型,是目前最快、最具控制性和最逼真的 Firefly 图像模型,支持生成逼真的图像,提供更高的分辨率(最高可达2K)和更精细的创意控制。
AI教程资讯
2023-04-14

Step1X-Edit 是阶跃星辰团队推出的通用图像编辑框架,能缩小开源图像编辑模型与闭源模型(如 GPT-4o 和 Gemini2 Flash)之间的性能差距。Step1X-Edit结合多模态大语言模型(MLLM)和扩散模型,基于处理参考图像和用户的编辑指令,提取潜在嵌入并生成目标图像。
AI教程资讯
2023-04-14

WebSSL(Web-scale Self-Supervised Learning)是Meta、纽约大学等机构推出的视觉自监督学习(SSL)系列模型,基于大规模网络数据(如数十亿图像)训练视觉模型,无需语言监督学习。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载