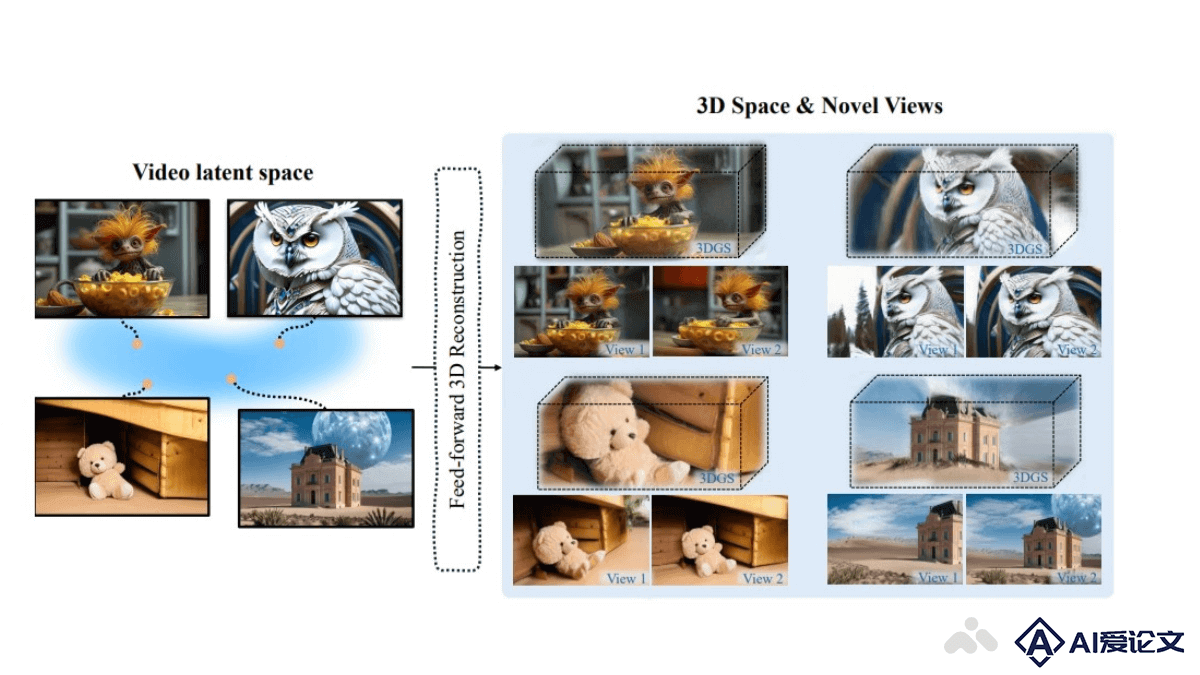
MIMO是什么
MIMO是阿里巴巴集团智能计算研究所推出的可控角色视频合成的新型AI框架,基于空间分解建模技术,将2D视频转换为3D空间代码,实现对角色、动作和场景的精确控制。MIMO能处理任意角色的合成,适应新颖的3D动作,并与真实世界场景交互。MIMO的核心在于将视频分解为主要人物、底层场景和浮动遮挡三个部分,然后分别编码为身份代码、运动代码和场景代码,用于合成过程的控制信号。不仅提高了合成视频的真实感,还增强了用户对视频内容的控制能力。

来源:爱论文 时间:2025-02-26 11:43:57
MIMO是阿里巴巴集团智能计算研究所推出的可控角色视频合成的新型AI框架,基于空间分解建模技术,将2D视频转换为3D空间代码,实现对角色、动作和场景的精确控制。MIMO能处理任意角色的合成,适应新颖的3D动作,并与真实世界场景交互。MIMO的核心在于将视频分解为主要人物、底层场景和浮动遮挡三个部分,然后分别编码为身份代码、运动代码和场景代码,用于合成过程的控制信号。不仅提高了合成视频的真实感,还增强了用户对视频内容的控制能力。
 相关资讯
更多+
相关资讯
更多+
MIMO是阿里巴巴集团智能计算研究所推出的可控角色视频合成的新型AI框架,基于空间分解建模技术,将2D视频转换为3D空间代码,实现对角色、动作和场景的精确控制。MIMO能处理任意角色的合成,适应新颖的3D动作,并与真实世界场景交互。
AI教程资讯
 2023-04-14
2023-04-14

豆包AI视频模型是字节跳动推出的两款AI视频生成大模型:PixelDance 和 Seaweed 。PixelDance基于DiT结构,擅长理解复杂指令,生成连贯、多主体交互的视频片段,适合制作故事性强的短片。Seaweed则基于Transformer结构,通过时空压缩技术训练,支持多分辨率输出,生成逼真、流畅的视频,适合多种商业应用场景。PixelDance适合需要复杂动作和故事叙述的视频创作,而Seaweed则适合需要高清晰度和逼真度的视频生成。
AI教程资讯
2023-04-14

美图奇想大模型(MiracleVision)是美图公司推出的一款AI视觉大模型,专注于美学创作,包括东方美学、人像和商业设计等。模型完成了视频生成能力的全面升级,能生成1分钟、每秒24帧、1080P分辨率的高质量视频,显著提升视频的画质、流畅性和真实性。
AI教程资讯
2023-04-14

SafeEar是由浙江大学和清华大学联合开发的AI音频伪造检测框架,保护用户隐私的同时检测音频伪造。采用基于神经音频编解码器的解耦模型,分离语音的声学信息和语义信息,用声学信息进行检测,有效防止隐私泄露。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载