SpatialVLA – 上海 AI Lab 联合上科大等推出的空间具身通用操作模型
来源:爱论文
时间:2025-03-10 09:43:12
SpatialVLA是什么
SpatialVLA 是上海 AI Lab、中国电信人工智能研究院和上海科技大学等机构共同推出的新型空间具身通用操作模型,基于百万真实数据预训练,为机器人赋予通用的3D空间理解能力。SpatialVLA基于Ego3D位置编码将3D空间信息与语义特征融合,用自适应动作网格将连续动作离散化,实现跨机器人平台的泛化控制。SpatialVLA 在大规模真实机器人数据上预训练,展现出强大的零样本泛化能力和空间理解能力,在复杂环境和多任务场景中表现突出。SpatialVLA 开源代码和灵活的微调机制为机器人领域的研究和应用提供了新的技术路径。
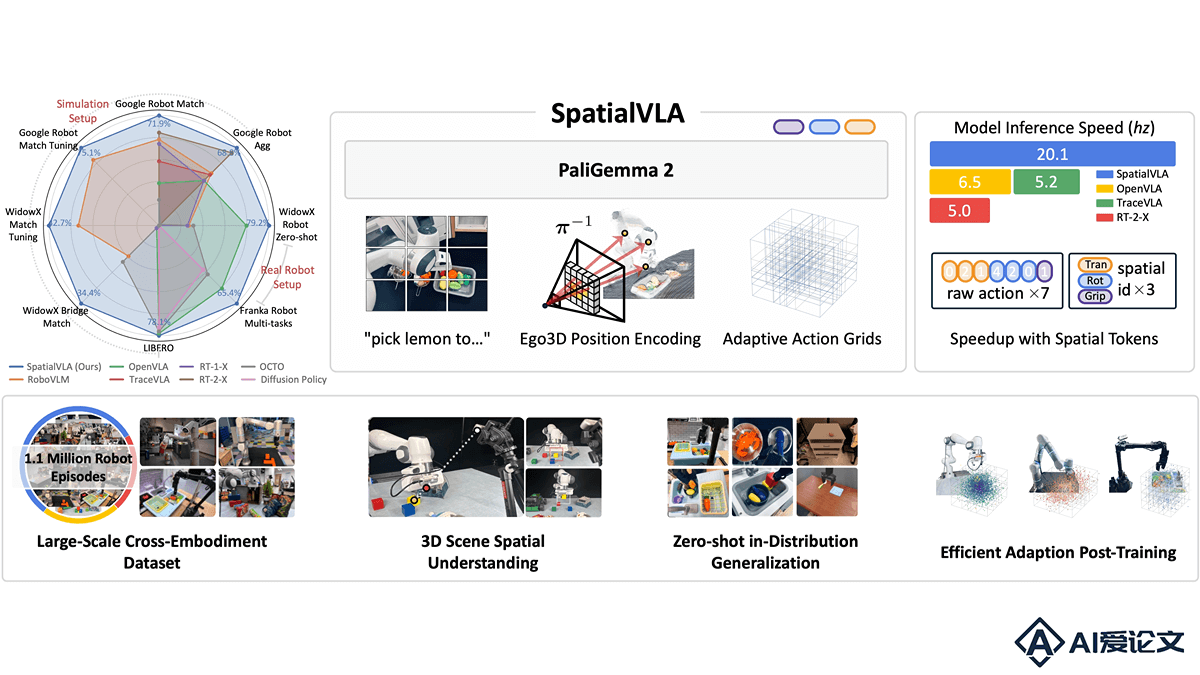
SpatialVLA的主要功能
零样本泛化控制:在未见过的机器人任务和环境中直接执行操作,无需额外训练。高效适应新场景:用少量数据微调,快速适应新的机器人平台或任务。强大的空间理解能力:理解复杂的3D空间布局,执行精准的操作任务,如物体定位、抓取和放置。跨机器人平台的通用性:支持多种机器人形态和配置,实现通用的操作策略。快速推理与高效动作生成:基于离散化动作空间,提高模型推理速度,适合实时机器人控制。
SpatialVLA的技术原理
Ego3D位置编码:将深度信息与2D语义特征结合,构建以机器人为中心的3D坐标系。消除对特定机器人-相机校准的需求,让模型感知3D场景结构适应不同机器人平台。自适应动作网格:将连续的机器人动作离散化为自适应网格,基于数据分布划分动作空间。不同机器人的动作用网格对齐,实现跨平台的动作泛化和迁移。空间嵌入适应:在微调阶段,根据新机器人的动作分布重新划分网格,调整空间嵌入。提供灵活且高效的机器人特定后训练方法,加速模型适应新环境。预训练与微调:在大规模真实机器人数据上进行预训练,学习通用的操作策略。在新任务或机器人平台上进行微调,进一步优化模型性能。
SpatialVLA的项目地址
项目官网:https://spatialvla.github.io/GitHub仓库:https://github.com/SpatialVLA/SpatialVLAHuggingFace模型库:https://huggingface.co/IPEC-COMMUNITY/foundation-vision-language-action-modelarXiv技术论文:https://arxiv.org/pdf/2501.15830
SpatialVLA的应用场景
工业制造:用于自动化装配和零件搬运,快速适应不同生产线,提高生产效率。物流仓储:精准抓取和搬运货物,适应动态环境,优化物流效率。服务行业:完成递送、清洁和整理任务,理解自然语言指令,适应复杂环境。医疗辅助:传递手术器械、搬运药品,确保操作精准和安全。教育与研究:支持快速开发和测试新机器人应用,助力学术研究。

 相关资讯
相关资讯 2023-04-14
2023-04-14



 下载
下载
















