DiffBrush – 北邮联合清华等机构推出的图像生成与编辑框架
来源:爱论文
时间:2025-03-10 13:47:35
DiffBrush是什么
DiffBrush是北京邮电大学、清华大学、中国电信人工智能研究所和西北工业大学推出的,无需训练的图像生成与编辑框架,支持用户基于手绘草图直观地控制图像生成。DiffBrush用预训练的文本到图像(T2I)模型,基于颜色引导、实例与语义引导及潜在空间再生等技术,精准控制生成图像的颜色、语义和实例分布。DiffBrush兼容多种T2I模型(如Stable Diffusion、SDXL等),支持LoRA风格调整,用户在画布上简单绘制实例的轮廓和颜色,能生成符合需求的图像。DiffBrush解决了传统T2I模型依赖文本提示的局限性,降低AI绘画的门槛,为用户提供更直观、高效的创作方式。
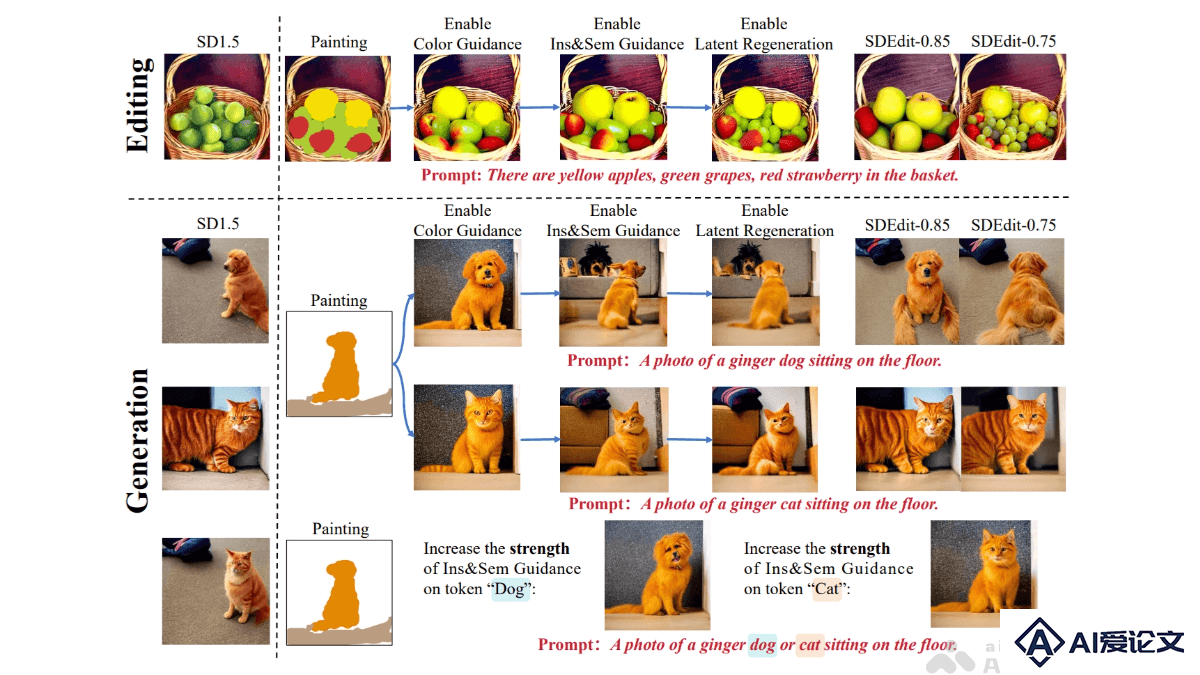
DiffBrush的主要功能
用户友好的图像生成:用户用手绘草图控制生成图像的内容,无需复杂的文本提示或技术知识。颜色控制:根据用户绘制的颜色信息,精确控制生成图像中对应区域的颜色。实例与语义控制:绘制实例的轮廓和标注语义信息,控制生成图像中特定对象的位置和语义属性。图像编辑:在已有图像的基础上进行编辑,例如添加、修改或替换图像中的对象。风格化生成:支持与LoRA(Low-Rank Adaptation)风格调整结合,生成具有不同艺术风格的图像,如油画、国画等。多模型兼容:与多种T2I模型(如Stable Diffusion、SDXL、Flux等)兼容,具有广泛的适用性。
DiffBrush的技术原理
扩散模型的引导机制:基于预训练的T2I模型(如Stable Diffusion)的扩散过程。扩散模型逐步去噪,将随机噪声映射为真实图像。DiffBrush修改扩散过程中的去噪方向,引导生成的图像向用户手绘的草图靠拢。颜色引导:基于扩散模型的潜在空间(latent space)与颜色空间的高度相似性,调整潜在空间中的特征,实现对生成图像颜色的精确控制。用户绘制的颜色信息被编码到潜在空间中,用能量函数(如MSE损失)引导生成图像的颜色与用户需求一致。实例与语义引导:基于扩散模型中的注意力机制(如交叉注意力和自注意力)实现实例和语义的控制。用户绘制的实例轮廓被用作注意力图的监督目标,基于调整注意力图的分布,确保生成图像中对象的位置和语义与用户需求一致。潜在空间再生:基于迭代优化初始噪声分布,接近用户手绘草图的目标分布,在扩散过程的早期阶段调整潜在空间,进一步优化生成图像的质量。用户交互与兼容性:将用户的手绘草图与文本提示相结合,用简单的用户界面实现直观的交互。DiffBrush支持多种预训练的T2I模型,用户根据需要调整引导强度等超参数,实现最佳生成效果。
DiffBrush的项目地址
arXiv技术论文:https://arxiv.org/pdf/2502.20904
DiffBrush的应用场景
创意绘画:艺术家和设计师快速将手绘创意转化为高质量图像,支持多种风格,方便实现艺术构思。图像编辑:在已有图片上添加、替换或修改内容,用简单手绘完成操作,适合普通用户和设计师。教育工具:用在艺术和设计教学,帮助学生通过手绘理解色彩、构图和创意表达。游戏设计:快速生成游戏场景、角色或动画草图,支持风格化输出,助力创意迭代。广告设计:根据创意草图快速生成广告图像,满足客户对色彩和布局的要求,提升设计效率。

 相关资讯
相关资讯 2023-04-14
2023-04-14



 下载
下载
















