Qwen2.5-Omni是什么
Qwen2.5-Omni 是阿里开源的 Qwen 系列旗舰级多模态模型,拥有7B参数,Qwen2.5-Omni具备强大的多模态感知能力,能处理文本、图像、音频和视频输入,支持流式文本生成与自然语音合成输出,能实现实时语音和视频聊天。Qwen2.5-Omni用独特的 Thinker-Talker 架构,Thinker 负责处理和理解多模态输入,生成高级表示和文本,Talker 将表示和文本转化为流畅的语音输出。模型在多模态任务(如 OmniBench)中达到最新水平,全维度远超Google的Gemini-1.5-Pro等同类模型。在单模态任务(如语音识别、翻译、音频理解等)中表现出色。Qwen2.5-Omni在Qwen Chat上提供免费体验,模型现已开源,支持开发者和企业免费下载商用,在手机等终端智能硬件上部署运行。

Qwen2.5-Omni的主要功能
文本处理:理解、处理各种文本输入,包括自然语言对话、指令、长文本等,支持多种语言。图像识别:支持识别和理解图像内容。音频处理:具备语音识别能力,将语音转换为文本,能理解语音指令,生成自然流畅的语音输出。视频理解:支持处理视频输入,同步分析视频中的视觉和音频信息,实现视频内容理解、视频问答等功能。实时语音和视频聊天:支持实时处理语音和视频流,实现流畅的语音和视频聊天功能。Qwen2.5-Omni的技术原理
Thinker-Talker 架构:基于Thinker-Talker 架构,将模型分为两个主要部分,Thinker作为模型的“大脑”,负责处理和理解输入的文本、音频和视频等多模态信息,生成高级语义表示和对应的文本输出。Talker作为模型的“嘴巴”,负责将 Thinker 生成的高级表示和文本转化为流畅的语音输出。时间对齐多模态位置嵌入(TMRoPE):为同步视频输入的时间戳与音频,Qwen2.5-Omni 推出新的位置嵌入方法 TMRoPE(Time-aligned Multimodal RoPE)。将音频和视频帧用交错的方式组织,确保视频序列的时间顺序。TMRoPE 将多模态输入的三维位置信息(时间、高度、宽度)编码到模型中,基于分解原始旋转嵌入为时间、高度和宽度三个分量实现。文本输入用相同的 ID,TMRoPE 与一维 RoPE 功能等效。音频输入将每个 40ms 的音频帧用相同的 ID,引入绝对时间位置编码。图像输入将每个视觉标记的时间 ID 保持不变,高度和宽度的 ID 根据标记在图像中的位置分配。视频输入用音频和视频帧的时间 ID 交替排列,确保时间对齐。流式处理和实时响应:基于块状处理方法,将长序列的多模态数据分解为小块,分别处理,减少处理延迟。模型引入滑动窗口机制,限制当前标记的上下文范围,进一步优化流式生成的效率。音频和视频编码器用块状注意力机制,将音频和视频数据分块处理,每块处理时间约为 2 秒。流式语音生成用 Flow-Matching 和 BigVGAN 模型,将生成的音频标记逐块转换为波形,支持实时语音输出。Qwen2.5-Omni 的三个训练阶段:第一阶段:固定语言模型参数,仅训练视觉和音频编码器,用大量的音频-文本和图像-文本对数据,增强模型对多模态信息的理解。第二阶段:解冻所有参数,用更广泛的数据进行训练,包括图像、视频、音频和文本的混合数据,进一步提升模型对多模态信息的综合理解能力。第三阶段:基于长序列数据(32k)进行训练,增强模型对复杂长序列数据的理解能力。Qwen2.5-Omni的项目地址
项目官网:https://qwenlm.github.io/blog/qwen2.5-omni/GitHub仓库:https://github.com/QwenLM/Qwen2.5-OmniHuggingFace模型库:https://huggingface.co/Qwen/Qwen2.5-Omni-7B技术论文:https://github.com/QwenLM/Qwen2.5-Omni/blob/main/assets/Qwen2.5_Omni在线体验Demo:https://huggingface.co/spaces/Qwen/Qwen2.5-Omni-7B-DemoQwen2.5-Omni的模型性能
多模态任务:在 OmniBench 等多模态任务中达到先进水平。单模态任务:在语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU, MMStar)、视频理解(MVBench)以及语音生成(Seed-tts-eval 和 subjective naturalness)等多个领域表现优异。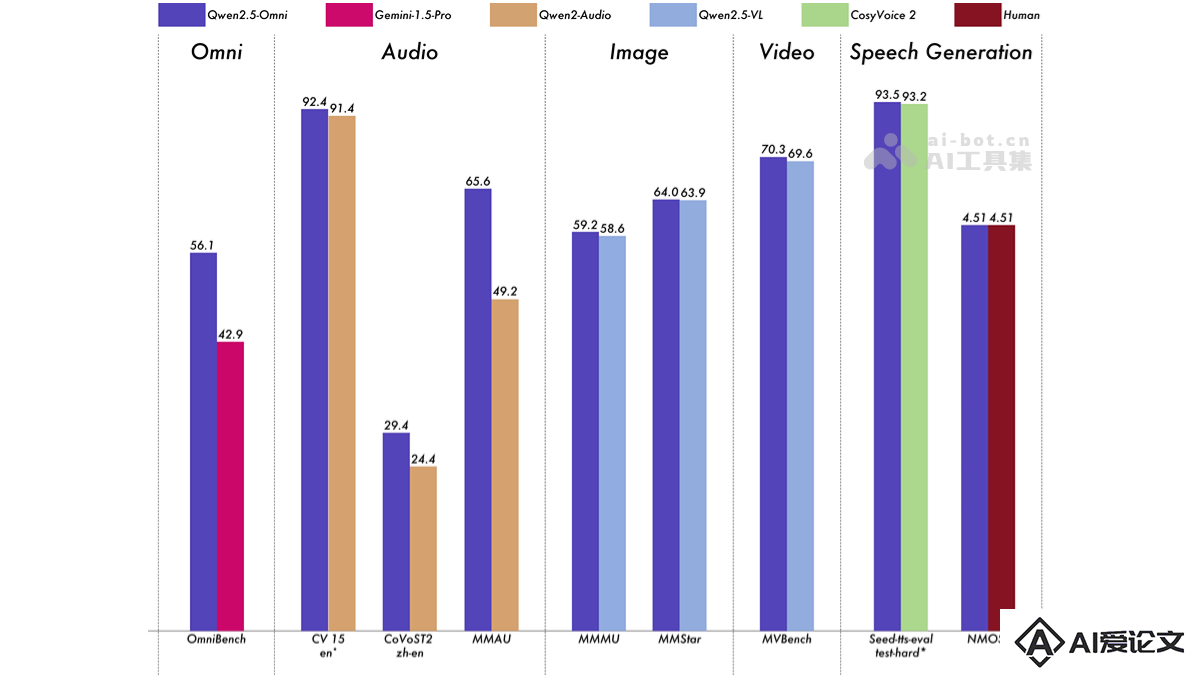
 相关资讯
相关资讯 2023-04-14
2023-04-14



 下载
下载