Unique3D是什么
Unique3D是清华大学团队开源的一个单张图像到3D模型转换的框架,通过结合多视图扩散模型和法线扩散模型,以及一种高效的多级上采样策略,能够从单张图片中快速生成具有高保真度和丰富纹理的3D网格。Unique3D结合ISOMER算法进一步确保了生成的3D模型在几何和色彩上的一致性和准确性,仅需30秒即可完成从单视图图像到3D模型的转换,生成效果优于InstantMesh、CRM、OpenLRM等图像转3D模型。

Unique3D的功能特色
单图像3D网格生成:Unique3D能够从单个2D图像自动生成3D网格模型,将平面图像转换为具有空间深度的三维形态。多视角视图生成:系统使用多视图扩散模型生成同一物体的四个正交视图图像,这些视图从不同方向捕捉物体的特征,为3D重建提供全面的视角信息。法线贴图生成:Unique3D为每个多视角图像生成对应的法线贴图,这些贴图记录了物体表面的朝向信息,对于后续的3D模型渲染至关重要,能够模拟光线如何与表面相互作用,增强模型的真实感。多级分辨率提升:通过多级上采样过程逐步提高生成图像的分辨率,从低分辨率到高分辨率(如从256×256到2048×2048),使得3D模型的纹理和细节更加清晰。几何和纹理细节整合:在重建过程中,Unique3D将颜色信息和几何形状紧密结合,确保生成的3D模型在视觉上与原始2D图像保持一致,同时具有复杂的几何结构和丰富的纹理细节。高保真度输出:生成的3D模型在形状、纹理和颜色上与输入的2D图像高度一致,无论是在几何形态的准确性还是纹理的丰富性上都达到了高保真度的标准。
Unique3D的官网入口
官方项目主页:https://wukailu.github.io/Unique3D/GitHub代码库:https://github.com/AiuniAI/Unique3D在线Demo体验:https://u45213-bcf9-ef67553e.westx.seetacloud.com:8443/Hugging Face Demo:https://huggingface.co/spaces/Wuvin/Unique3D模型权重下载:https://huggingface.co/spaces/Wuvin/Unique3D/tree/main/ckptarXiv技术论文:https://arxiv.org/abs/2405.20343Unique3D的技术原理
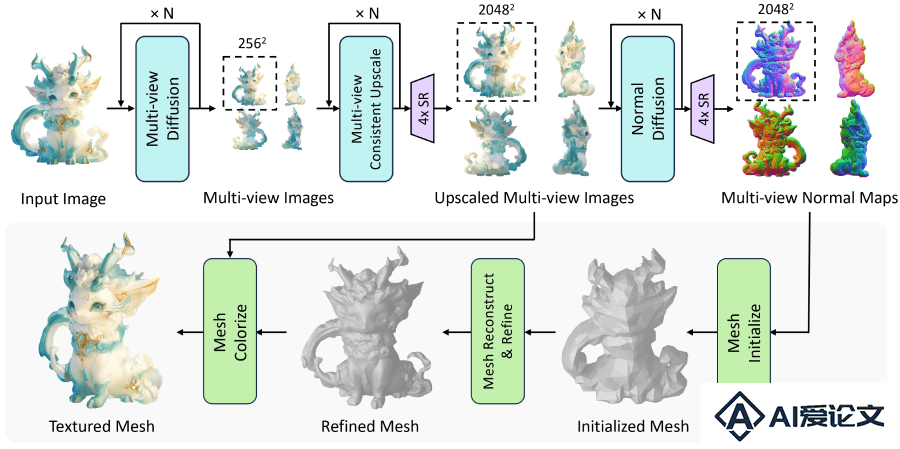 多视图扩散模型:利用扩散模型从单视图图像生成多视角(通常是四个正交视图)图像。这些模型通过训练学习2D图像的分布,并将其扩展到3D空间,生成具有不同视角的图像。法线扩散模型:与多视图扩散模型协同工作,为每个生成的视图图像生成对应的法线贴图,这些法线贴图包含了表面法线的方向信息,对后续的3D重建至关重要。多级上采样过程:采用多级上采样策略逐步提高生成图像的分辨率。初始生成的图像分辨率较低,通过上采样技术逐步提升至更高的分辨率,以获得更清晰的细节。ISOMER网格重建算法:一种高效的网格重建算法,用于从高分辨率的多视图RGB图像和法线图中重建3D网格。ISOMER算法包括:初始网格估计:快速生成3D对象的粗糙拓扑结构和初始网格。粗糙到精细的网格优化:通过迭代优化过程,逐步改善网格的形状,使其更接近目标形状。显式目标优化:为每个顶点指定一个优化目标,解决由于视角不一致导致的问题,提高几何细节的准确性。颜色和几何先验整合:在网格重建过程中,将颜色信息和几何形状的信息整合到网格结果中,以提高最终模型的视觉真实性和准确性。显式目标(ExplicitTarget):为每个顶点定义一个优化目标,这是一个从顶点集合到颜色集合的映射函数,用于指导顶点颜色的优化,提高模型的多视图一致性。扩展正则化(Expansion Regularization):在优化过程中使用的一种技术,通过在顶点的法线方向上移动顶点来避免表面塌陷,确保模型的完整性。颜色补全算法:针对不可见区域的颜色补全,使用一种高效的算法,将可见区域的颜色平滑地传播到不可见区域,确保整个模型颜色的一致性。
多视图扩散模型:利用扩散模型从单视图图像生成多视角(通常是四个正交视图)图像。这些模型通过训练学习2D图像的分布,并将其扩展到3D空间,生成具有不同视角的图像。法线扩散模型:与多视图扩散模型协同工作,为每个生成的视图图像生成对应的法线贴图,这些法线贴图包含了表面法线的方向信息,对后续的3D重建至关重要。多级上采样过程:采用多级上采样策略逐步提高生成图像的分辨率。初始生成的图像分辨率较低,通过上采样技术逐步提升至更高的分辨率,以获得更清晰的细节。ISOMER网格重建算法:一种高效的网格重建算法,用于从高分辨率的多视图RGB图像和法线图中重建3D网格。ISOMER算法包括:初始网格估计:快速生成3D对象的粗糙拓扑结构和初始网格。粗糙到精细的网格优化:通过迭代优化过程,逐步改善网格的形状,使其更接近目标形状。显式目标优化:为每个顶点指定一个优化目标,解决由于视角不一致导致的问题,提高几何细节的准确性。颜色和几何先验整合:在网格重建过程中,将颜色信息和几何形状的信息整合到网格结果中,以提高最终模型的视觉真实性和准确性。显式目标(ExplicitTarget):为每个顶点定义一个优化目标,这是一个从顶点集合到颜色集合的映射函数,用于指导顶点颜色的优化,提高模型的多视图一致性。扩展正则化(Expansion Regularization):在优化过程中使用的一种技术,通过在顶点的法线方向上移动顶点来避免表面塌陷,确保模型的完整性。颜色补全算法:针对不可见区域的颜色补全,使用一种高效的算法,将可见区域的颜色平滑地传播到不可见区域,确保整个模型颜色的一致性。  相关资讯
相关资讯 2023-04-14
2023-04-14



 下载
下载














