Llama 3.2是什么
Llama 3.2是Meta公司最新推出的开源AI大模型系列,包括小型和中型视觉语言模型(11B和90B参数)以及轻量级纯文本模型(1B和3B参数)。Llama 3.2模型专为边缘设备和移动设备设计,支持128K令牌的上下文长度,并针对高通和联发科硬件进行优化。Llama 3.2模型在图像理解和文本处理任务上具有高性能,并且通过torchtune进行定制化微调,使用torchchat部署到本地,推动了AI技术的开放性和可访问性。

来源:爱论文 时间:2025-02-26 12:04:08
Llama 3.2是Meta公司最新推出的开源AI大模型系列,包括小型和中型视觉语言模型(11B和90B参数)以及轻量级纯文本模型(1B和3B参数)。Llama 3.2模型专为边缘设备和移动设备设计,支持128K令牌的上下文长度,并针对高通和联发科硬件进行优化。Llama 3.2模型在图像理解和文本处理任务上具有高性能,并且通过torchtune进行定制化微调,使用torchchat部署到本地,推动了AI技术的开放性和可访问性。
 相关资讯
更多+
相关资讯
更多+
Llama 3 2是Meta公司最新推出的开源AI大模型系列,包括小型和中型视觉语言模型(11B和90B参数)以及轻量级纯文本模型(1B和3B参数)。Llama 3 2模型专为边缘设备和移动设备设计,支持128K令牌的上下文长度,并针对高通和联发科硬件进行优化。
AI教程资讯
 2023-04-14
2023-04-14

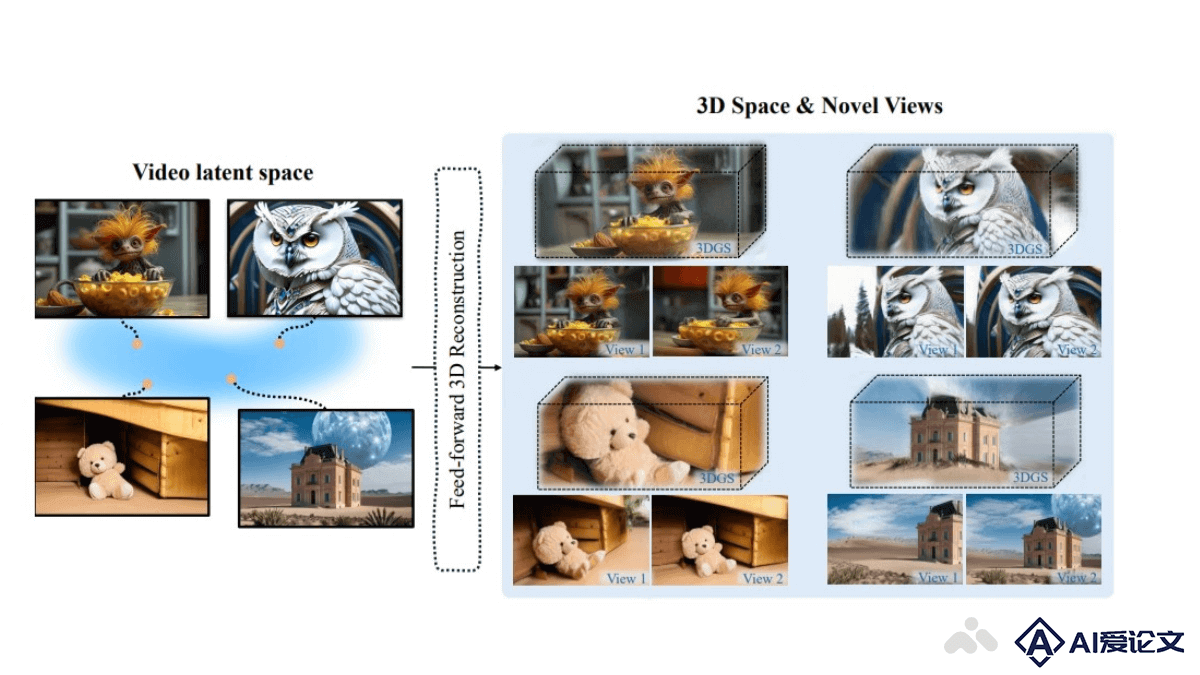
MIMO是阿里巴巴集团智能计算研究所推出的可控角色视频合成的新型AI框架,基于空间分解建模技术,将2D视频转换为3D空间代码,实现对角色、动作和场景的精确控制。MIMO能处理任意角色的合成,适应新颖的3D动作,并与真实世界场景交互。
AI教程资讯
2023-04-14

豆包AI视频模型是字节跳动推出的两款AI视频生成大模型:PixelDance 和 Seaweed 。PixelDance基于DiT结构,擅长理解复杂指令,生成连贯、多主体交互的视频片段,适合制作故事性强的短片。Seaweed则基于Transformer结构,通过时空压缩技术训练,支持多分辨率输出,生成逼真、流畅的视频,适合多种商业应用场景。PixelDance适合需要复杂动作和故事叙述的视频创作,而Seaweed则适合需要高清晰度和逼真度的视频生成。
AI教程资讯
2023-04-14

美图奇想大模型(MiracleVision)是美图公司推出的一款AI视觉大模型,专注于美学创作,包括东方美学、人像和商业设计等。模型完成了视频生成能力的全面升级,能生成1分钟、每秒24帧、1080P分辨率的高质量视频,显著提升视频的画质、流畅性和真实性。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载