WeGen – 中科大联合上海交大等推出的统一多模态生成模型
来源:爱论文
时间:2025-03-10 14:08:56
WeGen是什么
WeGen 是中国科学技术大学联合上海交通大学、微信团队、中国科学院等机构推出的统一多模态生成模型,基于自然对话实现多样化的视觉生成任务。WeGen结合多模态大语言模型(MLLM)和扩散模型,处理文本到图像生成、条件驱动生成、图像编辑、风格迁移等多种任务。WeGen 的核心优势能在用户指令较模糊时提供多样化的创意输出,在用户有具体需求时保持生成结果与指令和参考图像的一致性。WeGen 基于动态实例一致性(DIIC)数据管道和提示自重写(PSR)机制,解决实例身份一致性和生成多样性两大挑战,展现出作为用户友好型设计助手的潜力。
WeGen的主要功能
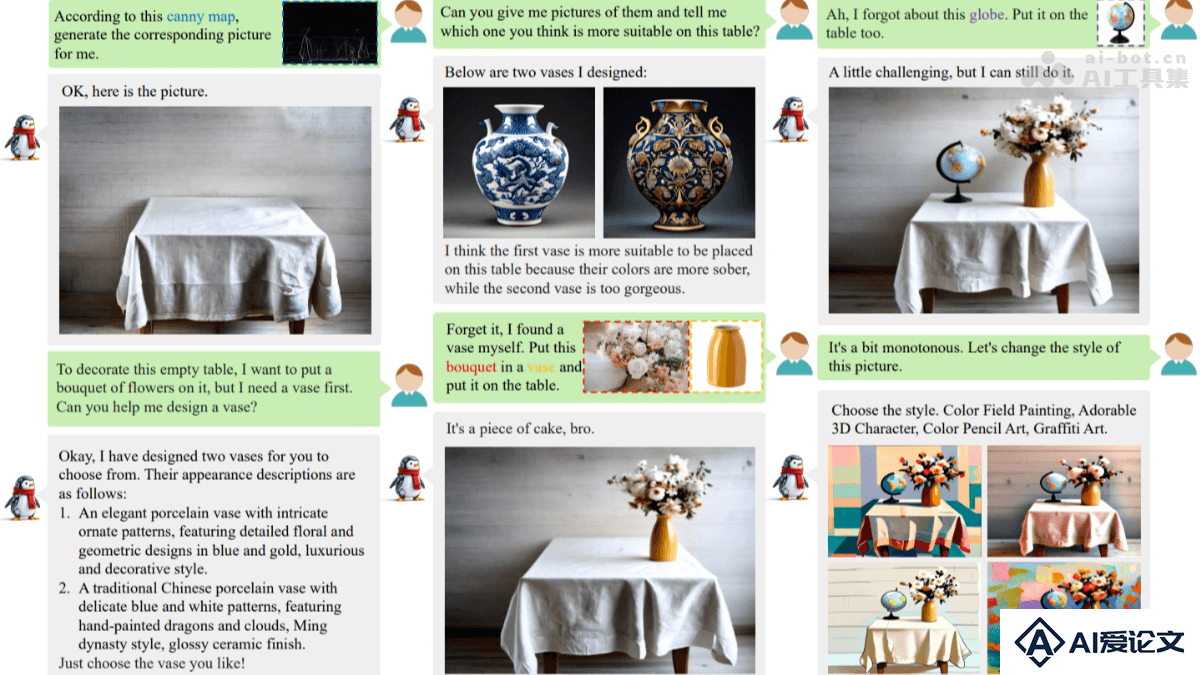
文本到图像生成:根据文本描述生成高质量的图像。条件驱动生成:基于特定条件(如边缘图、深度图、姿态图)生成图像。图像编辑与修复:对现有图像进行修改、修复或扩展。风格迁移:将一种图像的风格应用到另一张图像上。多主体生成:在生成图像时保留多个参考对象的关键特征。交互式生成:基于自然对话与用户交互,逐步优化生成结果。创意设计辅助:为用户提供多样化的生成选项,激发创意。
WeGen的技术原理
多模态大语言模型(MLLM)与扩散模型结合:基于CLIP作为视觉编码器,将图像转化为语义特征;用扩散模型(如SDXL)作为解码器,生成高质量图像。,LLM(如LLaMA)处理自然语言指令,实现文本与视觉信息的融合。动态实例一致性(DIIC):用视频序列跟踪对象的自然变化,保持其身份一致性。DIIC数据管道解决传统方法在实例身份保持上的不足,让模型在修改图像时保留关键特征。提示自重写(PSR)机制:基于语言模型重写文本提示,引入随机性,生成多样化的图像。PSR用离散文本采样,让模型探索不同的解释,保持语义一致性。统一框架与交互式生成:WeGen将多种视觉生成任务整合到一个框架中,基于自然对话与用户交互,逐步优化生成结果,保留用户满意的部分。大规模数据集支持:WeGen从互联网视频中提取的大规模数据集进行训练,数据集包含丰富的对象动态和自动标注的描述,帮助模型学习一致性和多样性。
WeGen的项目地址
GitHub仓库:https://github.com/hzphzp/WeGenarXiv技术论文:https://arxiv.org/pdf/2503.01115
WeGen的应用场景
创意设计:帮助设计师快速生成创意概念图,激发灵感,适用于广告、包装、建筑等领域。内容创作:为影视、游戏、动漫等行业生成场景、角色或道具的概念图,加速创作流程。教育辅助:生成与教学内容相关的图像,帮助学生更直观地理解抽象概念。个性化定制:根据用户需求生成定制化的设计方案,如服装、家居装饰等。虚拟社交与娱乐:生成虚拟形象、场景或道具,增强虚拟社交和游戏的体验感。

 相关资讯
相关资讯 2023-04-14
2023-04-14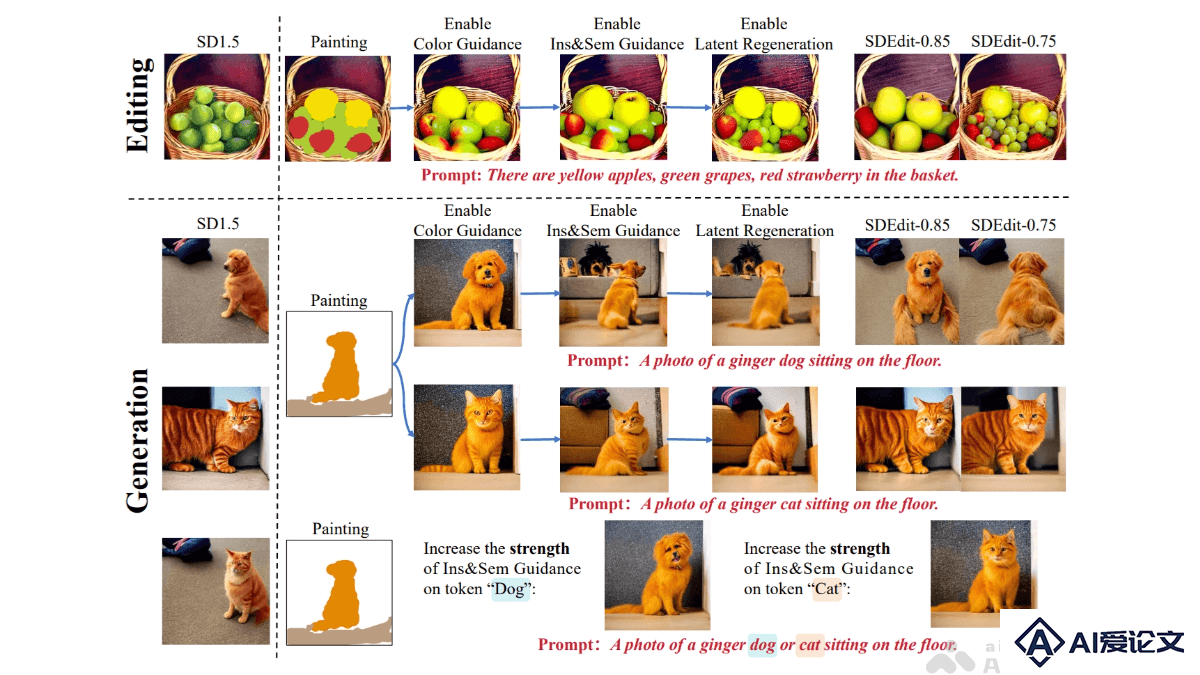



 下载
下载
















