PortraitGen是什么
PortraitGen是中国科学技术大学研究团队推出的一款AI人像视频编辑工具。基于3D高斯溅射技术和神经高斯纹理机制,将2D人像视频转换为4D高斯场,实现高质量的3D和时间一致性编辑。工具支持多模态编辑,包括文本驱动、图像驱动编辑以及重新照明,能快速、高效地对视频中的人物进行风格化、换衣、光照调整等操作。通过面部感知编辑和表达式相似性指导,PortraitGen确保编辑后的肖像自然且与原始视频帧保持一致性。

来源:爱论文 时间:2025-02-26 12:59:08
PortraitGen是中国科学技术大学研究团队推出的一款AI人像视频编辑工具。基于3D高斯溅射技术和神经高斯纹理机制,将2D人像视频转换为4D高斯场,实现高质量的3D和时间一致性编辑。工具支持多模态编辑,包括文本驱动、图像驱动编辑以及重新照明,能快速、高效地对视频中的人物进行风格化、换衣、光照调整等操作。通过面部感知编辑和表达式相似性指导,PortraitGen确保编辑后的肖像自然且与原始视频帧保持一致性。
 相关资讯
更多+
相关资讯
更多+
PortraitGen是中国科学技术大学研究团队推出的一款AI人像视频编辑工具。基于3D高斯溅射技术和神经高斯纹理机制,将2D人像视频转换为4D高斯场,实现高质量的3D和时间一致性编辑。
AI教程资讯
 2023-04-14
2023-04-14

MMMLU(多语言大规模多任务语言理解)是由OpenAI推出的一个开源数据集,旨在评估和提升人工智能模型在不同语言、认知和文化背景下的性能而设计。MMMLU建立在广受欢迎的大规模多任务语言理解(MMLU)基准的基础上,数据集包含57个不同学科领域的任务,从基础数学到复杂的法律和物理问题,覆盖广泛的主题和难度级别。
AI教程资讯
2023-04-14

Llama 3 2是Meta公司最新推出的开源AI大模型系列,包括小型和中型视觉语言模型(11B和90B参数)以及轻量级纯文本模型(1B和3B参数)。Llama 3 2模型专为边缘设备和移动设备设计,支持128K令牌的上下文长度,并针对高通和联发科硬件进行优化。
AI教程资讯
2023-04-14

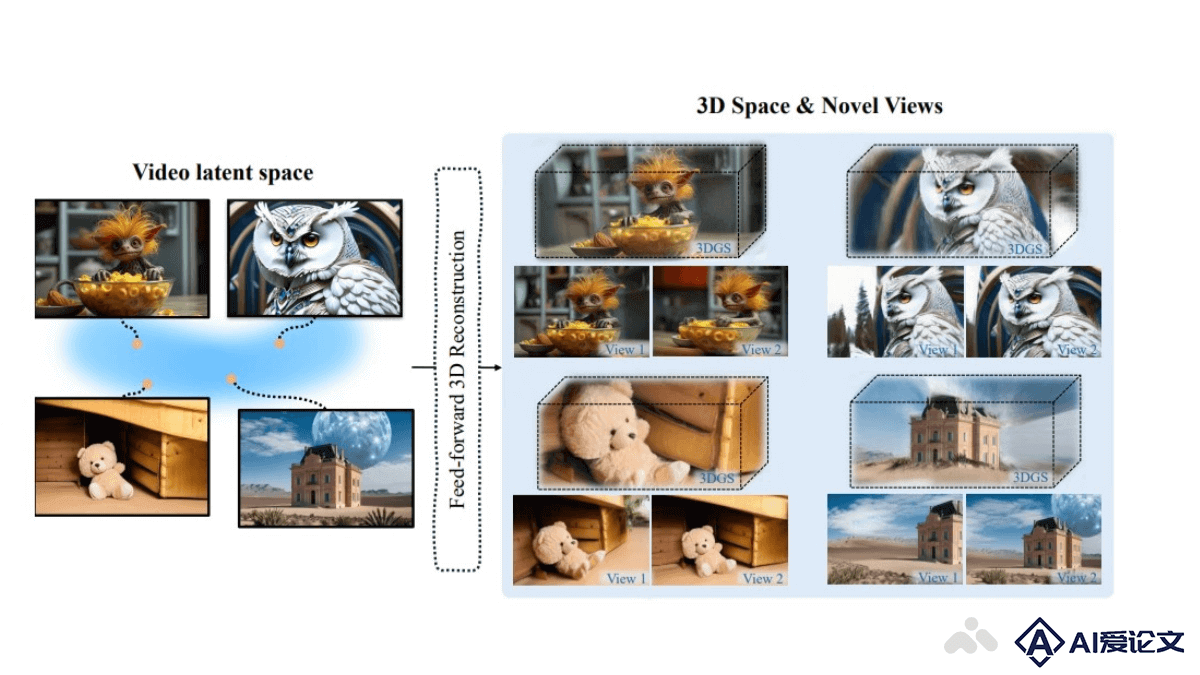
MIMO是阿里巴巴集团智能计算研究所推出的可控角色视频合成的新型AI框架,基于空间分解建模技术,将2D视频转换为3D空间代码,实现对角色、动作和场景的精确控制。MIMO能处理任意角色的合成,适应新颖的3D动作,并与真实世界场景交互。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载